LLM-Orc-Station
Multi-provider LLM orchestrator built for a school-grade question answering app. Routes student queries to the cheapest model that can handle them, rotates API keys automatically, and simulates 1,000 concurrent users in your terminal.
Timeline
Role
Status
CompletedTechnology Stack
LLM-Orc-Station
Multi-provider LLM orchestrator built for a school-grade question answering app.
Routes student queries to the cheapest model that can handle them, rotates API keys automatically, and simulates 1,000 concurrent users in your terminal.
Architecture
Student prompt
│
▼
classifier.ts ← classifies prompt complexity: simple / medium / complex
│
▼
router.ts ← picks model based on policy + complexity
│ cost: simple→mock, medium→flash, complex→pro
│ latency: always pick fastest
│ fallback: pick by health score
▼
keymngr.ts ← picks best available key (round-robin, skips open breakers)
│
▼
dispatcher.ts ← calls Gemini REST API (or mock if no real key)
│
▼
metrics.ts ← logs: timestamp, userId, model, keyId, latencyMs, ok
│
▼
orchestrator.ts ← retries on failure (up to 2 more attempts with fallback policy)File Map
| File | Responsibility |
|---|---|
types.ts | All TypeScript interfaces (ApiKey, Model, LogEntry, etc.) |
classifier.ts | Complexity scoring: simple / medium / complex |
registry.ts | Model catalog, key storage, and key selection |
keymngr.ts | Key rotation lifecycle and circuit breaker logic |
router.ts | Routing policies: cost, latency, fallback |
dispatcher.ts | Actual HTTP call to Gemini (or mock response) |
orchestrator.ts | Single-query flow with retry logic |
metrics.ts | In-memory store: P95, per-model stats, time buckets |
simulator.ts | 1000-user CLI simulator with concurrency pool |
server.ts | Express HTTP API |
index.ts | Entry point: server mode or simulate mode |
Quick Start
Prerequisites
bun installRun the simulator (no API key needed — uses mock responses)
# Default properties
bun run src/index.ts simulate
# Or with custom settings:
bun run src/index.ts simulate 1000 50 cost
# ^ ^ ^
# users conc policyRun the HTTP server
bun run src/index.tsThen in another terminal:
# Single query
curl -X POST http://localhost:3000/query \
-H "Content-Type: application/json" \
-d '{"prompt": "What is 7 times 8?", "userId": "u1", "persona": "grade-school"}'
# View metrics
curl http://localhost:3000/stats
# View key state
curl http://localhost:3000/keys
# Manually rotate keys for flash model
curl -X POST http://localhost:3000/rotate/flash
# Start 1000-user simulation via API
curl -X POST http://localhost:3000/simulate \
-H "Content-Type: application/json" \
-d '{"users": 1000, "policy": "cost", "concurrency": 50}'Use a real Gemini API key (optional)
# .env file
GEMINI_API_KEY=AIzaSy...
Note: Without a real key, dispatcher automatically returns varied mock responses. The routing, rotation, circuit breaker, and metrics all still work correctly.
How Each Part Works
1. Classifier (classifier.ts)
Analyses the prompt text using heuristics (no LLM call needed — that would be recursive!):
| Signal | Result |
|---|---|
| Pure arithmetic, ≤ 8 words | simple |
| Over 120 words | complex |
| Academic verbs: "analyse", "compare", "evaluate" | complex |
Two or more ? in prompt | complex |
| Over 40 words | medium |
| Explanation verbs: "explain", "describe", "summarise" | medium |
| Code keywords: "code", "function", "algorithm" | medium |
| Default | simple |
Why heuristics and not an LLM? Calling a model to decide which model to call adds latency and cost on every request. Heuristics are deterministic, instantaneous, and easy to tune.
Edge case: short but complex prompts "Prove the Riemann hypothesis" is 4 words but clearly complex. The
COMPLEX_VERBSlist catches "prove" → complexity = complex.
2. Model Registry (registry.ts)
Three models:
| Model | Tier | Cost/1M tokens | Avg Latency | RPM |
|---|---|---|---|---|
mock | Free | $0 | 25ms | ∞ |
gemini-flash | Budget | $0.075 | 800ms | 100 |
gemini-pro | Capable | $3.50 | 2000ms | 30 |
Each model starts with 2 keys. pickKey() sorts by usage ascending (least-used key wins). This is round-robin in practice without needing a separate counter.
Edge case: all keys revoked
getUsableKeys()returns empty →pickKey()returnsnull→ router escalates to next model tier → if all models exhausted, orchestrator returns a503-style response.
3. Key Rotation (keymngr.ts)
Time-based rotation (every 5 minutes by default):
t=0 key-A active, key-B active
t=5m key-C added (active), key-A → deprecated
t=7m key-A → revoked (grace period elapsed)
t=10m key-D added (active), key-B → deprecatedWhy keep deprecated keys alive? Any in-flight request that already selected key-A must be allowed to finish. The 2-minute grace period covers even slow Gemini Pro calls. Revocation only happens after the grace period so no request gets a mid-flight key error.
Usage-based rotation (every 100 successful requests per key): Prevents any single key from burning its quota limit. Checked in the same background sweep as time-based rotation.
Circuit Breaker states per key:
closed ──[3 consecutive fails]──► open ──[30s cooldown]──► half ──[success]──► closed
└──[fail]────► openclosed: Normal operationopen: Key is skipped entirely bygetUsableKeys()half: One "probe" request is allowed through to test recovery
Edge case: last key standing
rotateKeys()checksactiveKeys.length === 0before proceeding. If somehow all keys are deprecated/revoked, rotation is skipped rather than leaving you keyless.
4. Router (router.ts)
cost policy (default for school app):
- simple → tries mock first, then flash, then pro
- medium → tries flash first, then pro, then mock
- complex → tries pro first, then flash, then mock If chosen model has no usable key, escalates down the list automatically.
latency policy:
- Sorts by
avgLatencyascending (mock=25ms first) - Returns first model with a usable key
fallback policy:
- Scores each model:
usableKeys × (1 - errorRate) - Sorts descending → healthiest model wins
- Used automatically on retries in orchestrator
5. Orchestrator (orchestrator.ts)
Flow for each query:
- Classify prompt → complexity
- Route(complexity, policy) → model + key
- Dispatch call → response or error
- On error: record failure (circuit breaker), log, retry with "fallback" policy
- Max 2 retries (3 total attempts)
- Log to metrics regardless of outcome
Why retry with "fallback" not the original policy? If "cost" policy chose
gemini-flashand it failed, retrying with "cost" picks the same model again (same problem). "Fallback" picks the healthiest different model, maximising chance of recovery.
6. Metrics (metrics.ts)
Tracked per-request: Timestamp, userId, persona, complexity, model, keyId, latencyMs, ok/fail.
Aggregated:
- Total requests / errors / error rate
- Average latency and P95 latency (95th percentile of all latency values)
- Per-model: requests, errors, errorRate, avgLatency
- Per-key: usage count
- Time-series buckets (5s granularity, 10min window) for charts
P95 vs Average: Average latency hides tail latency. If 950 requests take 100ms and 50 take 5000ms, average = 347ms but P95 = 5000ms. Students experiencing the P95 case are the ones filing bug reports. P95 is what you should optimise.
7. Simulator (simulator.ts)
Concurrency pool pattern:
pool size = 50
[user-001] → query → query → query → done
[user-002] → query → query → done
[user-003] → query → query → query → query → done
...as each user finishes, the next one startsThis prevents the "thundering herd" problem where 1000 simultaneous connections overwhelm even a local server.
Personas and their prompt banks:
| Persona | Complexity mix | Example prompt |
|---|---|---|
grade-school | ~80% simple | "What is 7 times 8?" |
middle-school | ~60% medium | "Explain how photosynthesis works." |
high-school | ~70% complex | "Analyse the themes of power in Macbeth." |
teacher | ~50% complex | "Design a rubric for evaluating student essays." |
This naturally creates a realistic distribution without hardcoding percentages.
Think time (500ms–2000ms between queries) prevents unrealistically rapid-fire requests from a single user.
Configuration
Environment variables
# .env file
GEMINI_API_KEY=AIzaSy... # Optional. Without it, mock responses are used.
PORT=3000 # Default: 3000Rotation timing (edit keymngr.ts)
const ROTATION_INTERVAL_MS = 5 * 60 * 1000; // 5 minutes
const GRACE_PERIOD_MS = 2 * 60 * 1000; // 2 minutes
const MAX_USAGE_BEFORE_ROTATE = 100; // per key
const BREAKER_FAIL_THRESHOLD = 3; // consecutive fails
const BREAKER_COOLDOWN_MS = 30_000; // 30 secondsSimulator settings
# Starts the simulator with syntax:
# bun run src/index.ts simulate [totalUsers] [concurrency] [policy]
bun run src/index.ts simulate 500 25 latency
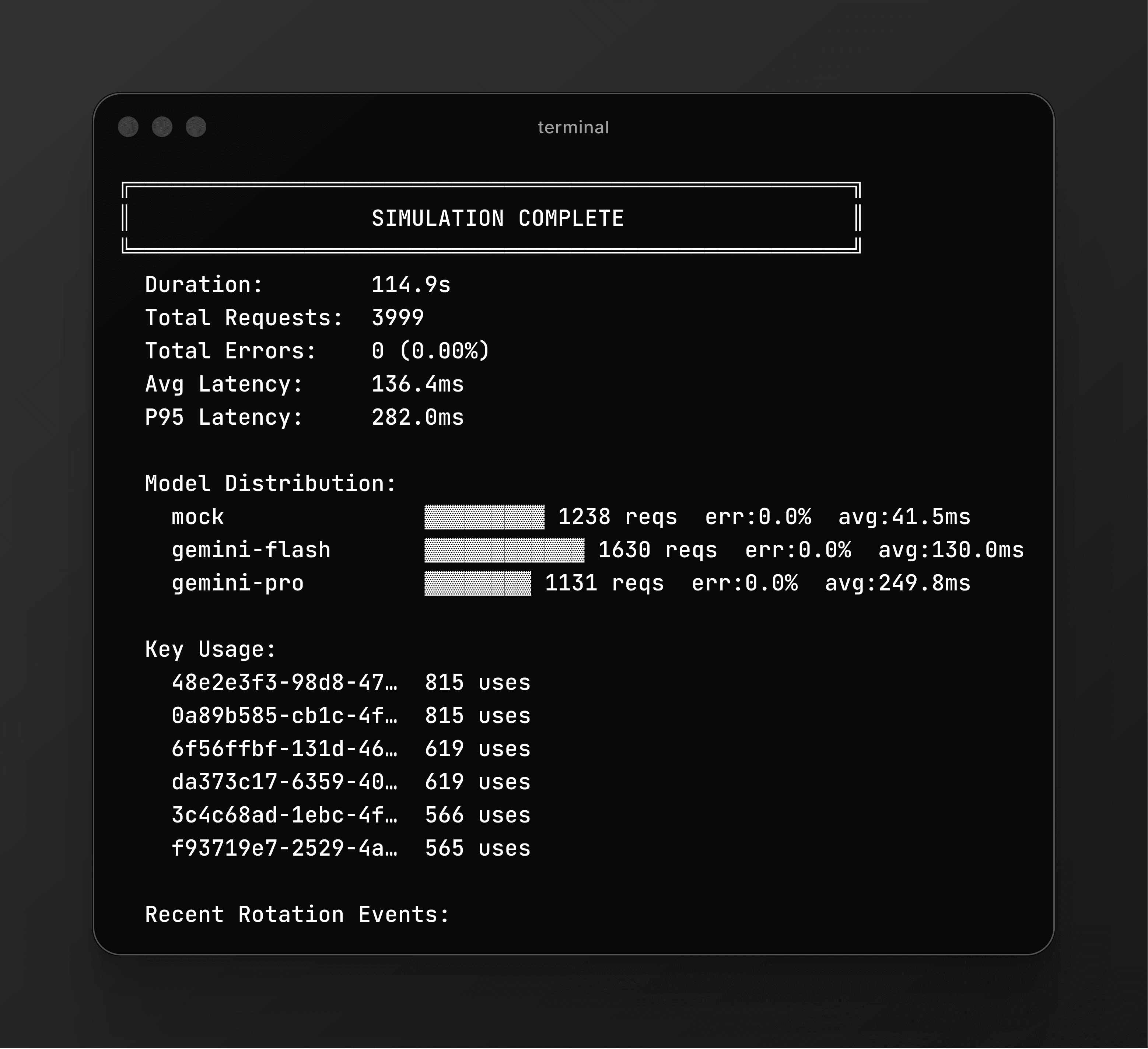
bun run src/index.ts simulate 2000 100 costSample Output
╔══════════════════════════════════════════════════════╗
║ LLM-Orc-Station Simulator Starting ║
╚══════════════════════════════════════════════════════╝
Users: 1000
Queries/user:~4
Concurrency: 50
Policy: cost
[████████████████████████████████████░░░░] 92.3% (3692/4000) elapsed: 38.2s
╔══════════════════════════════════════════════════════╗
║ SIMULATION COMPLETE ║
╚══════════════════════════════════════════════════════╝
Duration: 41.5s
Total Requests: 4000
Total Errors: 0 (0.00%)
Avg Latency: 287ms
P95 Latency: 812ms
Model Distribution:
mock ▓▓▓▓▓▓▓▓▓▓▓▓ 1580 reqs err:0.0% avg:26ms
gemini-flash ▓▓▓▓▓▓▓▓▓▓▓▓ 1610 reqs err:0.0% avg:812ms
gemini-pro ▓▓▓▓▓▓ 810 reqs err:0.0% avg:2003ms
Key Usage:
3f8a1b2c-4e5d… 792 uses
7a2c9d1e-3f8b… 788 uses
...
Recent Rotation Events:
[2026-02-23T10:05:00.000Z] flash: +3f8a1b2c deprecated:7a2c9d1eKnown Limitations and Stretch Goals
- Redis not integrated — Metrics live in memory and reset on restart. For multi-instance or persistent metrics, replace the
metricsobject with Redis calls. - Real key creation —
rotateKeys()adds a fake UUID key. In production, call your provider's key management API and inject the real secret. - Rate limiting — The RPM field on each model is tracked but not enforced as a hard cap. Add a token bucket or leaky bucket per model to enforce it.
- Prometheus export —
getStats()returns JSON. Wrapping it with a/metricsendpoint in Prometheus text format would enable Grafana dashboards.